Self-service Platform for building Speech Recognition Models
Our tech leadership contributed to an open source ASR toolkit which can
be used to build state of the art ASR models from scratch using lesser
resources and faster roll outs resulting in AI innovation in spoken
languages
About Company
The company is a non-profit organisation in ed-tech having the mission is to improve literacy and numeracy by enhancing access to learning opportunities for 200 million children in India.
Challenge
Lack of indigenous Cognitive capabilities in Indic Languages
Mostly Google/Amazon/Azure provides the Cognitive capabilities and there is no indigenous capability
Even Google/Amazon focus only on top 5-6 Indic languages. There is not a good support for other regional languages as well.
The current ASR models are data hungry and rely on lot of labeled dataset
Lack of tools and support for building own ASR models
Lack of datasets
Solution
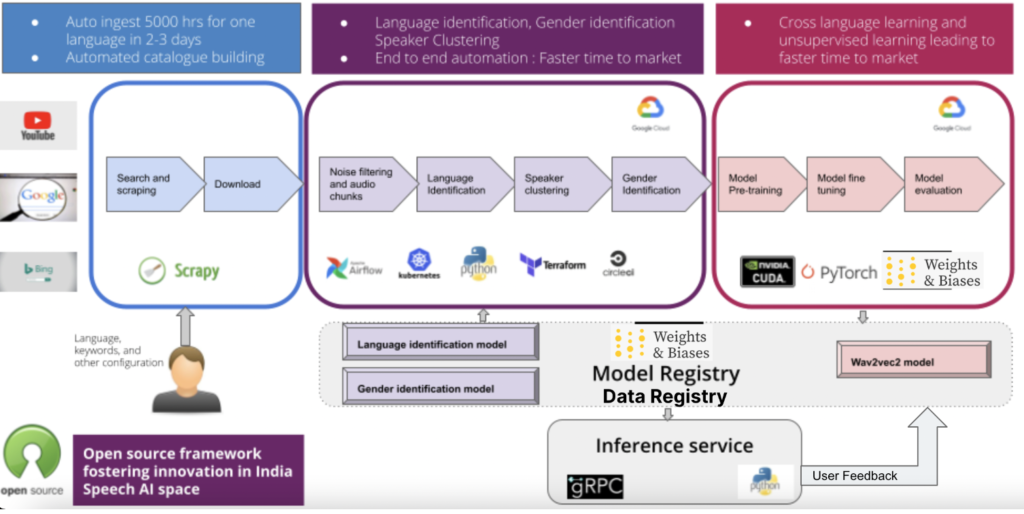
Built an open source self service speech recognition platform which can be used for data acquisition, data preparation, feature generation, model creation and model deployment on click of few buttons.
Semi Supervised approached was used which solved the problem of labelled speech data scarcity.
Platforms
Built an end to end MLOps pipeline for building datasets and deep learning models for Speech recognition.
Provided thought leadership on data strategy and created strategies for data acquisition, data analysis, data filtering, data identification of audio datasets.
The platform was built on GCP and airflow for building the orchestration pipeline.
All the required infrastructure could be built just by running few commands using Terraform