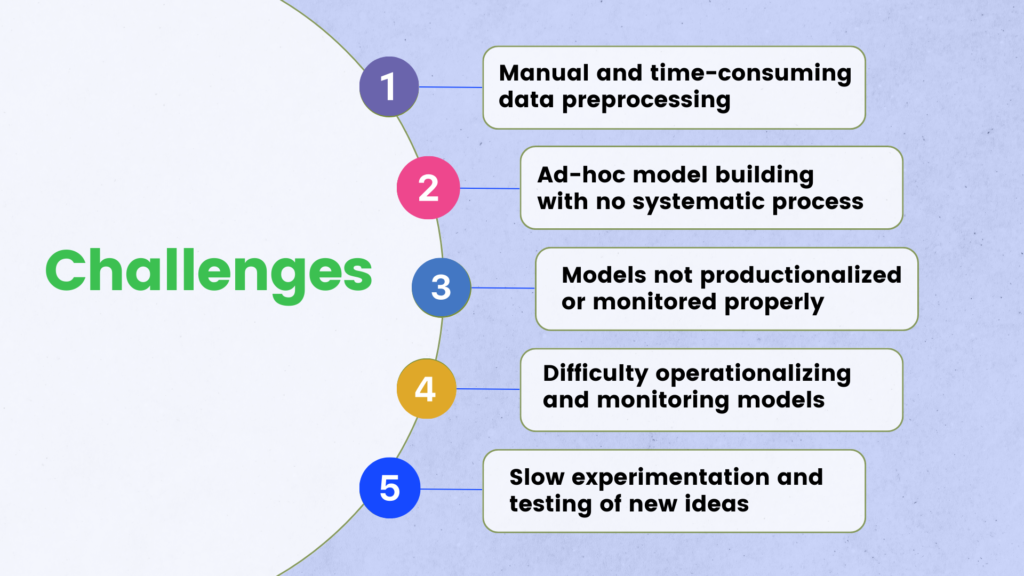
Many organizations struggle with executing end-to-end data science projects. Data preprocessing is manual and time-consuming. Model building involves ad-hoc experimentation and is not systematic. Productionalizing and monitoring models is an afterthought.
This leads to suboptimal model performance, slow experimentation, and difficulty operationalizing predictions. Data scientists spend more time on engineering versus research.
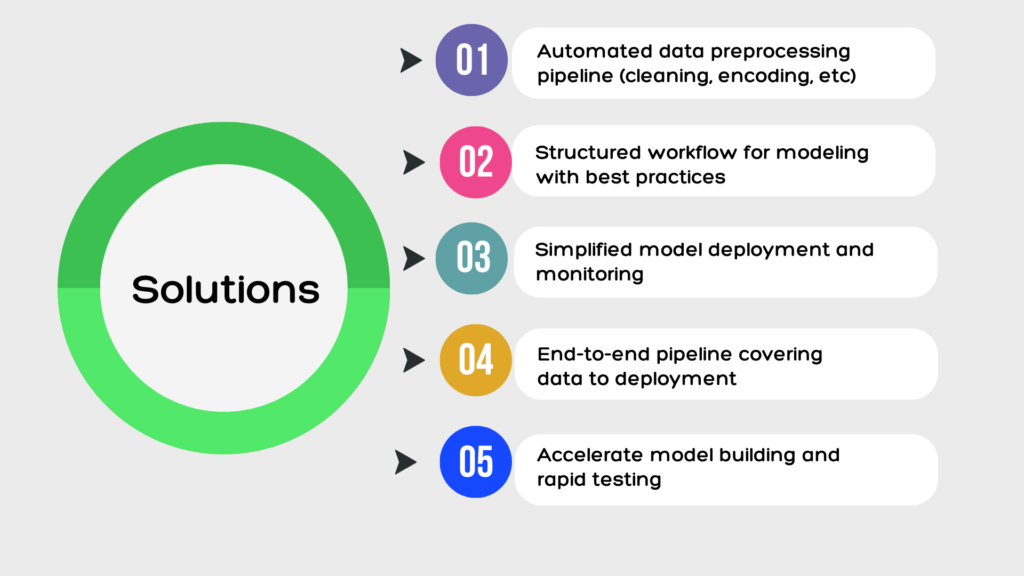
Our all-in-one data science pipeline solves these challenges by providing a standardized workflow from data to deployment. The pipeline automates tedious preprocessing tasks, enables structured modeling and evaluation, and simplifies model deployment and monitoring.
With our solution, organizations can accelerate model development, rapidly test new ideas, and reliably deploy models to production. Data scientists are freed to focus on high-value tasks like feature engineering and model tuning rather than plumbing.
By streamlining the full lifecycle, we empower teams to build better models faster. Our pipeline turns ad-hoc model building into a reproducible science. Get in touch today to learn how our solution can increase productivity, model quality, and operational reliability for your data science projects.
How Cortex helps:
Low code kit for enabling DS to build models faster and with right practices and steps.
This includes model operationalization [next milestone]
This kit enables DS to write the end to end pipelines for Preprocessing, Modeling and Inference
Introducing the All-in-One Data Science Pipeline – From Preprocessing to Modeling and Inference
Our new 3-phase pipeline provides everything you need for robust data science workflows.
Key Benefits:
– Faster model building
– Best practices imbibed in the development process
– Automation reduces manual errors and saves time
– Standardized workflows for consistent modeling
– Flexibility to customize and tune each phase
– Transparency, logging, and reproducibility
– Scalable inference pipeline for production
With our automated pipeline, data scientists can build better models faster. The workflow covers the full lifecycle – from raw data to deployed predictions. Get in touch for a demo and take the pain out of your next data science project!